Part 5 of Microsoft Most Valuable Professional and Fusion’s Chief Data Officer, Dave Shook’s 9-part educational series discussing various topics for asset-intensive industrial companies who need analytical insights to improve operations. The fifth part of this series is the topic of OT Data Ingestion to the Cloud.
There are a number of different reasons.
A lot of data pertaining to configuration information, changes in the configuration of the control system, or for that matter, in the instrument data itself, that information has a finite lifetime. For compliance or long-term performance reasons, you might want to hold on to that data for a long period of time. It can be very inexpensive to retain data for the long term in the cloud.
You don’t have to worry about networking among different systems because the data’s all been brought up to the cloud. Also, some data from third-party systems, like vibration monitoring systems, often ends up in the cloud to begin with. Basically, it’s transmitted directly from those systems through a cell or direct network connection to a vendor’s cloud location. So that data is already a cloud resident.
Computation on site is owned; it’s a capital asset which means that it is constrained. So if you want to run a high computational load job, like a simulation of an oil reservoir over a period of years using seismic data, you will need lots and lots of computers to do that or you will need a very long time in order to do that. In the cloud, you can rent those CPUs for when you need them.
Services like certain analytic AI/ML are really only available online. In that case, you got to get the data up to the cloud just to be able to use the services.
Near real-time data can be extremely useful. That’s the sort of streaming data use case, and that’s the case; whereas data is created here, we read it rapidly from our data acquisition client and push it up to the clouds so that it can be analyzed with low latency.
For example, streaming. Let’s say it’s sub one minute from a source to the cloud. That can be very effective if you’re looking to do high-speed analytics, but industrially most analytics that has to run that fast once they’re in production tend to run down here in the DMZ or even down in the control system itself. So the value of bringing streaming data up to the cloud in an industrial environment kind of depends on the use case.
There’s also a downside to streaming data, which is that, in many cases, when you’re acquiring data from something like a historian. If we’re bringing data once a minute basis or less, it is possible for that historian to receive updates on data that is old. So data that took longer than usual to get to it. And in that case, it may not show up in the streaming data set depending on the problems, are the architecture and design of that particular system. Batch data transfer is typically done at longer intervals but has a better chance of delivering a complete data set. Practically speaking, you tend to need both streaming and batch for industrial data acquisition to the cloud.
MQTT is a data transport protocol. It is relatively lightweight, which means to say that it doesn’t use a lot of CPU. It’s not hard to program. It does not impose a very heavy burden on the network.
In contrast, OPC is much heavier but contains a lot more information about the source system. We can think of this as more complete. They both are used in different domains. OPC is used extensively in an environment where you have a good network, decent power out in the field, and intelligent machines. You’ve got power in both electrical computing and robust networks. MQTT tends to be used in the process industry SCADA world as well. There are strengths and weaknesses to both protocols. But they are two of the most commonly used.
AMQP was extensively used in banking and probably still is, but it never really caught on in the industrial IoT space.
There are a number of proprietary ones. They are quite honestly a pretty good fit for the purpose, but the problem always is interoperability with proprietary ones.
One issue could be surround surrounding and opening up the possible vectors of attack to the operational environment when we get out to the cloud. However, the security argument is actually pretty well managed. It’s less about security and more about cost these days.
If we think about the computing that happens down in the controller, we have high-frequency data, so multiple values a second. We also have low compute latency, so multiple calculations a second. We also have significant consequences of failure. We can see that these three dimensions really determine where you want to put compute. As you move further to the right, this gets into the Purdue Reference model. It really says that as you move further away from the instrument, the time span around, which you’re making a decision increases, but the scope of the decision increases. So you start with down here, and you’re doing with one instrument and milliseconds as you come up to higher and higher levels, you go to broader and broader scopes and longer and longer cycles.

So up in the cloud, the data should primarily be used for either building or configuring the calculations that are going to run on-premise or to help people deal with integrated data for decision-making so that people can make those decisions.
Part 4 of Microsoft Most Valuable Professional Dave Shook, Fusion’s Chief Data Officer’s 9-part educational series discussing various topics for asset-intensive industrial companies who need analytical insights to improve operations. The fourth part of this series is the topic of Secure Management of Data Acquisition from the Cloud.
From the cloud or from a computer at some arbitrary location, possibly connecting by way of the internet, we want to be able to configure this data acquisition client to securely collect data from a historian, an alarm historian, or direct from a control system.

First of all, we remember that all of the communications are initiated outbound from the client to the relay point and then from the relay point up to the cloud. These are secured in transit, and both ends are authenticated against each other so that we know that this data acquisition client is talking to who it needs to and the IoT Hub knows who’s talking to it.
The most convenient way for us to manage the data acquisition is to leverage that communication channel transmitting data. Microsoft has allowed us to do this using the IoT Hub Cloud To Device messaging, which we refer to in this context as our control plane. We will be sending control commands down. It is still an Outward Bound connection, but once that connection has been made, the IoT Hub can send information down to the data acquisition client, and then it will Implement them, and it’ll add more tags or retrieve more history or stop acquiring data, whatever the command happens to be.
That is nice and secure. But, we now need to worry about how a user can enter and act with that system, and we can know that they are who they are. First, we need this data acquisition management application in Azure – think of it as a website. This user needs to be able to talk to that, and that then sends commands to the IoT hub. The IoT Hub then sends the commands back down over the same channel using the control plane.
First of all, Microsoft gives us Fusion a lot of help here with the active directory and Azure active directory. That makes it possible for an active directory authenticated user to be mapped directly into Azure. Secondly, multi-factor authentication, which is where you have to respond to a text or an authentication application, makes it much less likely that a user can be spoofed by a malicious actor.
These tools make it very unlikely that anyone other than authenticated users can do this, but we still need to have end-to-end security of the communication channel. That’s where we get into things like a VPN, connecting this computer to the Azure endpoint. In fact, practically speaking, this whole system should be within a VPN anyway because it’s a logical extension of the DMZ. A user can do things here that can directly affect the DMZ, and so this should be secured about as tightly as a DMZ is itself.

What we do at Fusion is use some network best practices with Azure to make it so that the user, or even go so far as to put a computer certificate so that the computer itself is authenticated. In that case, what we know is that it’s that user. We know that it’s that computer. We know there’s no man in the middle. And therefore, it is valid and secure for us to allow that user to perform the administrative actions that they should be permitted to do, and then the communication through the IoT has a control plane, giving us secure communication down to the data acquisition client.
Part 3 of Microsoft Most Valuable Professional Dave Shook, Fusion’s Chief Data Officer’s 9-part educational series discussing various topics for asset-intensive industrial companies who need analytical insights to improve operations. The third part of this series is the topic of Secure Communication from DMZ to the Cloud.

The DMZ is a network that exists because the distributed control system or industrial control system needs to be protected from the Business Network. Even well-intentioned users in the Business Network, to say nothing of malicious users or malicious software, inadvertently cause operating incidents by overloading the control system Network, accidentally interfering with individual servers on the network, etc. Over the course of the last 20 years or so, there has been a standard network configuration set up in which the most important part is this notion of a demilitarized zone known as DMZ.
The idea is that the distributed control system has a firewall between it and the DMZ, and the DMZ has a firewall between the Business Network. The control system is a logically separated network from the Business network. For instance, the control system’s entire active directory, user authentication, and device authentication system are completely segregated from the Business Network. This means this makes the control system much more secure and protective from a Business Network. However, we do need to be able to get data from the control system to the outside world. This is where the DMZ comes in. The DMZ is also where applications run that need to be able to access data on the control system and may also need to access data in the Business Network.
We’re trying to get data from devices, controllers, servers, and other control systems up to the cloud. There are many layers to industrial security, but the couple I want to talk about is that all connections must be outbound. So all connections must start being made outbound, and you cannot have any single communication that passes through two firewalls in a row. There needs to be a landing point in between the two firewalls, and you need to be able to change ports and protocols for those two firewalls so that you don’t have the same hole or the same exploit into the success of firewalls.
The issue here is in order to acquire data from these Industrial Systems, it becomes necessary to put some sort of client software or data collector at least in the DMZ, possibly down in the control system itself. That data collector then has to pass the data through to something sitting on the Business Network, some sort of relay station, and then the relay station can forward the data up to the cloud. While this works, there are other ways of doing this, but they are kind of fraught from a network analysis security point of view, and they’re nonstandard. You are best off having this sort of relay station in the way. The other thing is so outward bound, no two firewalls – also, this network does not trust the Business Network, just like the Business Network does not trust the internet. That’s really the crux of the matter.
Now what we have done at Fusion and what Microsoft has done is we are using a Microsoft construct called Nested Edge. Nested Edge allows us to put some software out of the Business Network, that is, IoT Edge Software from Microsoft. This behaves as though it were an IoT hub from the data collector’s point of view, and it then connects onward to the IoT hub. The nice thing about this is it works both ways. It works for data collection being sent up to Azure, and also it works from a control plane point of view so that certain messages and information sent through the Azure IoT Hub control plane can be relayed down to the data collector.
The reason why that is actually secure has to do with both the limitations on the type of message that can be sent from here, so this cannot do absolutely everything, and also the limitations down at the data collector of what messages it’s prepared to accept. This configuration works even with multiple firewalls in a row and multiple relays in a row, and it makes it possible for this data collection system to go all the way up. You can even have an extension of the DMZ itself within Azure working as a virtual Network and then talking through an Azure firewall to the Azure Business Network.

You can carry on this notion of a DMZ up to the cloud and have as tight security over this Cloud DMZ extension as you do over the on-premise one if you choose to go that way. It is not necessary to go that way if all you’re doing is managing the retrieval of data, but if you’re getting into things like sending commands down, then at that point, it becomes really important that you get into this notion of DMZ extension.
Part 2 of Microsoft Most Valuable Professional Dave Shook, Fusion’s Chief Data Officer’s 9-part educational series discussing various topics for asset-intensive industrial companies who need analytical insights to improve operations. The second part of this series is the topic of Operational Data Types.

There are several specific types of operational data and the fact that different ones exist and how many there make life a little bit complicated. The single most common type of data that people think about when they talk about operational data is what we call time series. Time series data is the data that comes from instruments or that goes out as commands. The thing about time series data is there is always an identifier that we typically refer to as a tag. It takes on values over time, so it’s a time series, and it’s always within the context of a single tag or possibly multiple tags together. But, one time series is one identifier.
This data comes in packages consisting of an identifier, a timestamp, a value, and the quality. The quality tells us whether the value itself is of any use, and if not, why not. But it always comes in in this sort of bundle of data. Alarms events are quite different. They can be things like high temperatures, or they can be things like batch complete. The thing is that alarm and event data are not structured the same. It doesn’t have a single identifier and a single timestamp. Often these things will have a start time and an end time. The fact that it has it set up with an interval means that it’s not a times series. Also, what happens is that there’ll be some sort of object – might be a batch, might be an instrument, piece of equipment, and there will often be some sort of topic alarm or even high alarm and low alarm. Then there’ll be a bunch of values, and the values are a function of the topic. So we now get into this world where it’s more relational than this simple time series structure.
For example, look at a vibration monitoring system, which is more like an IoT device. What we have here are we’ll have an identifier, and that’ll be for the sensor or the location. But the problem is that it doesn’t send raw data because the data that comes in here might come in at 10,000 Hertz, so 10,000 values a second. It doesn’t make sense to send all that data up to the cloud. Instead, what it does at some timestamp is that it will put together a bundle of data, like an array of 2048 raw value, an FT or Power Spectrum, which is 2048 outputs plus a bunch of features. The features depend on configuration as well as the specific manufacturer model. These are things like the total power or what frequency the biggest peaks are at – that kind of thing. This is a much more complex data set than the alarms and events and far more complex than a simple time series. This is just one example of the type of complex data structure that can come up from operations.
In addition to this, there is metadata. The simplest form of metadata for any given measurement is the engineering units. It matters whether this is in degrees Celcius or degrees Fahrenheit. It matters whether it’s in feet per second, meters per second, and so on. There are also things like validity limits. A lot of instruments have hard limits on minimum and maximum that they can measure accurately. Provenance – the origin of the data is also important. This metadata is associated with any single measurement or value that comes in. It changes from time to time, so we need to retrieve it.
And finally, there’s something called context. The issue with context is this if we look at this vibration monitoring system, it is configured to understand that these two vibration sensors are 90 degrees apart on a particular bearing and that it will probably be configured to know that these two bearings are on the same pump. It may be configured to know that these bearings on this pump are connected to a shaft from that motor which also has these measurements.
That’s as far as it goes. The context information within the vibration monitoring system knows nothing about the process context. It only knows about the equipment context for the equipment it is monitoring.
But for us as Engineers or people analyzing what’s going on, the process operating context is as important as the equipment context. The problem here is that each source system has a data model. But there’s more than one, and they will overlap because they refer to the same physical environment. They are not necessarily configured in such a way that they know about it, and they’re not necessarily configured consistently. So this context information and these data models also need to be acquired and brought up to the cloud.
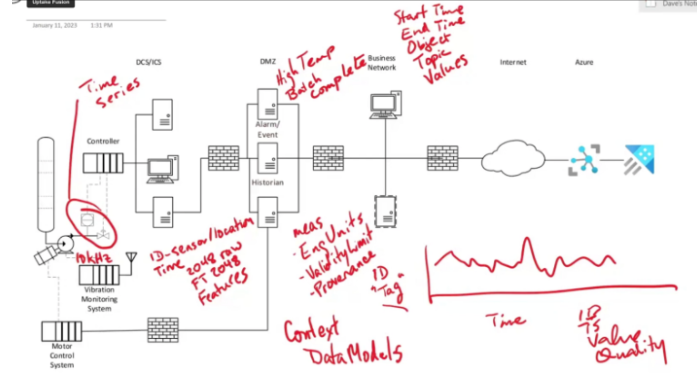
In summary, we’ve covered five quite distinct types of data – time series, alarms and events, complex sensor device record, metadata, and context.
Microsoft Most Valuable Professional Dave Shook, Fusion’s Chief Data Officer, dives into a 9-part educational series discussing various topics for asset-intensive industrial companies who need analytical insights to improve operations. The first part of this series is the topic of Data Acquisition from OT (Operational Technology) Systems.

Located in the picture above, we have some industrial equipment, a pump, a motor, a flow meter, and a flow transmitter controller –that control the flow rate all as part of a distributed control system or industrial control system firewall. Then there is a demilitarized zone or DMZ Network. Then another firewall goes through the corporate business network. Then another firewall goes out to the internet and into Microsoft Azure or a specific cloud.
Before moving forward, it is critical to first discuss the complexity involved in acquiring this operational technology. The process data, the flow rate, and the actions taken by the controller are collectible from the control system itself. The technology for doing this is pretty mature and is largely, but not entirely, based on a set of protocols called OPC. Most control systems support OPC, or you can get OPC connectors. Usually, what happens is there’s something called a historian running in the DMZ that collects these values at some interval and stores them locally.
In addition to those signals and calculations in the control system, it can also detect alarms or other events. This data is structurally different from the data in a historian. It tends to live in an alarm and event database often abbreviated as A&E. This data is quite different from the historian data in terms of the data structures and how it’s queried so it tends to live in a different system. Unfortunately, there are additional data pertaining to the operations that do not even make it into the historian of the alarms and events server.
For example, the motor control and things like vibration measurement often don’t make it into the control system directly. Instead, there’s an auxiliary set of computers either specifically for vibration monitoring or almost certainly for motor control. These systems are sophisticated in their own right and have quite complex computations. But the control system often does not digest the data they produce. So you might get a small, thin subset of the data transmitted to the control system so the operator can detect if something has gone badly wrong or so the operator can start to stop the motor controllers. But a lot of the data in vibration systems and motor control systems tends to be stranded in the control system or even stranded upstream of the control system. To make any meaningful analysis of this equipment, especially in the context of the overall process, you often need to put some sort of auxiliary data acquisition system in place to collect the data from the vibration system or from the motor control systems and get that data out to the cloud.
These days, with intelligent IoT devices and intelligent monitoring devices, sometime systems can communicate all on their own up to the cloud because they’re just doing monitoring and they’re not capable of affecting the process. They don’t have to move through this series of firewalls necessarily, but you still have to acquire that data.

In order to be able to do meaningful analytics in the cloud based on your operating data, you need to acquire the operating data first. With Fusion, what we do and encourage others to put some data acquisition client with your DMZ or even on the auxiliary networks, if possible, that can then transport that data up to Azure. Then can deal with the fact that historian data or OPC data s structurally different from alarms and events. That vibration data is structurally different from simple flow measurements, and so on.
This is the fourth part of the Fusion Fundamentals series with Suchi Badrinarayanan, Business Consultant, at Fusion. This series focuses on liberating and normalizing OT data to accelerate enterprise-wide adoption and high business value realization of AI/ML. The fourth topic is Industrial Strength Data Liberation – Advantages.

When we’re talking about industrial strength software and getting operational technology data into a format where analytics can access it in a robust manner, you will need industrial strength software, which is what Fusion is designed for. The larger the data volumes become, the more you’ll need an industrial-strength software, and that’s exactly what Fusion represents.
Regardless of whether you have a thousand or a million tags, the latency will remain the same and we have very high performance.
We are able to do automatic Gap detection and backfill, especially when we have first-party connectors to those source systems.
You can ensure that your data reliability is very consistent. You will not have people going back into the source systems and going through all levels of the firewall to get their data. It is located in an accessible place for them.
That way, you do not pay for extra storage in Azure.
Also, there are some other things we can do around the metadata transport and the hierarchy. It just depends on if those are available from the source system. We’re able to move and adjust the metadata transport and the hierarchy into the cloud. However, if the metadata transport and the hierarchy are not available, then we can always use a different source where that hierarchical information would be located.
Furthermore, Fusion does a lot with data quality and data preprocessing to ensure that the data landing in the cloud is analytics-ready. We ensure that the data has no gaps as far as the source system is concerned and that any error messages are filled are filtered out.
Historians are notoriously very precarious. In case there’s ever a load increase on the historian, or if there are multiple users who are pulling out trends, etc., we make sure that we make sure we monitor the CPU usage, and if it goes above a certain amount, we throttle back our historical upload. That way, the customer is ensuring that the production system is still gathering that data because it is still very important to continue for that to continue to happen.
If available to us, we will collect uncompressed data as well. For any data science purposes, that’s something that could be very important. All of this data can go to any sort of data lake with multiple different deployment options.
We have created a tender for easy visualization of the data. We’ve realized that this is a gap in the market right now where there are not a lot of options to visualize data that are within the cloud. So we have a simple trender that you can use to save trends, view trends, and even share trends with other people.
With Fusion, we are able to align all of the data for analytics purposes. No matter where that data is coming from, whether it’s coming from five different historians and IoT sensors, the way that you access that data will always the same. None of this is actually a black box. It’s all open and available for your end-users to use in any way they prefer. Fusion does not try to constrain you in any way – your data is yours. We want you to use it as much as possible.

One critical advantage of Fusion is security. Fusion is Purdue-Model compliant, and we are heavily investing in nested Edge compatibility with Microsoft. If you have data within your level two or three of your Purdue Model, we have many customers who use Fusion to extract that data. We can do it in a very secure manner and tailor Fusion for everyone’s different security needs.
Fusion is not one size fits all. Fusion is very flexible and adapts to the customer’s specific needs.
Another important thing to note is that Fusion is pretty cost-effective. So you can pay for the drink on the ingestion side or pay for the drink on the consumption side. Whichever works best for the customer – we are amenable to ensuring Fusion is incredibly cost-effective for you.
Lastly, the most important thing is that Fusion helps accelerate any of your analytics use cases. So we are compliant with your enterprise cloud and in architecture because we follow a Microsoft-recommended architecture. But, once that data is there, you can use it for any use case or any third-party tool. We don’t restrict you in any way from getting that information moving. The deployment’s very fast. It typically takes us less than two weeks, and some customers even installed it on their own because of permissions required to get us access to their cloud.
The third part of the Fusion Fundamentals series with Suchi Badrinarayanan, Business Consultant, at Fusion. This series focuses on liberating and normalizing OT data to accelerate enterprise-wide adoption and high business value realization of AI/ML. The third topic is Cloud – Ingest, Store, and Consume OT Data.

What we are trying to do at Fusion and what we’ve achieved with many companies is creating an Industrial Analytics Data Hub. So that any use case can grab that data and provide business value for their company; so in less than two weeks, we can typically install this and have data flowing. We’re able to do that securely and in a way where the data is reliably moved over. Then we can also extract any additional information that’s within that system in the first place. So that means any metadata that’s relevant, any hierarchical data that’s relevant and combining all these data into a single repository – a single data hub where it’s then applicable for any use case.

We have first-party connectors to a lot of the sources that you see on the left side of the photo above. There are some that we’re still working on that we should have by this year. But those first-party connectors allow us to do some interesting things, such as having very low latency for real-time streaming data. This allows us to do multi-year historical batches that can be different for different tags depending on the use case. This also allows us to view any configuration changes that happen in the source system, such as if the hierarchy changes or if the metadata changes. These first-party connectors are constantly looking at that OT source and making sure that if any changes are occurring on that system that they move over as well, too, and get reflected in the cloud.
Also, if available, we can also move over event frames or any sort of right vibration analysis that happens, anything from IoT sensors, which is becoming very popular now. We can move all of that data over in a secure manner.
Once that data is available to us. We typically install our product fusion in our customers’ Cloud. There are a couple of cases where we host for various reasons, but for security purposes in terms of data, most of our customers ask us to implement this solution in their Azure tenant. We also do not try to mine that data for any reason. That data typically comes in through an IoT hub or equivalent. It comes in through the most secure manner and then can be used for any sort of use case that you can imagine.
For example, we have a lot of customers using Azure Data Explorer, but if you prefer Synapse, that’s an easy thing for us to manage as well. Or the customer can you other third-party solutions.
All in all, this allows Fusion to be that central point where all of that data comes in. It’s normalized, so you are querying it all the same way. It’s mapped to OPC standard and has some other data cleansing.
When your consumers of that data are using that data, we ensure

The data gets created with the things at the bottom: pumps, rigs, drills, drives, motors, rollers, boilers, flues, breakers, compressors, conveyors, and cables. These assets all generate data; this can vary from temperature readings to pressure readings or to vibration readings. Any kind of information that these assets generate is then usually stored in some place, but first, they have to be generated by a process, and then it’s communicated through multiple different ways to all of these data acquisition systems.

Typical data acquisitions are operations management, historians, SCADA/ Control Systems, PLC/ controllers, field inspections, instrument analyzers, IoT devices/meters, and IoT Sensors/ video/ audio. All of those things are producing data that gets acquired by all of these different systems, and then companies are trying to figure out a way to join all of this different data from all of these different sources to do analytics on them. That data can be real-time streaming data. It can be batch data. Typically you want it to have pretty low latency because if you want to do any near to real-time optimization.
Furthermore, you want it to be able to acquire data from any sort of historian, any sort of PLC, and any sort of SCADA system because most companies have a variety of all of these systems and are all collecting this data from these systems in a regular fashion. It is typically not just a one done. You want to collect all of this data for prolonged periods of time, so all of the analysis is up to date. This data is not only just the historical data and the real-time streaming data, but you also want to collect any metadata from these assets as well. In order to leverage that as well as any events in your analysis going forward.

Now that you have access to that data, you want to make sure that that data gets accessed into one Central Industrial data hub. That Hub can then provide the data and any additional information (such as the metadata, the hierarchy, or any events) to other systems. Then it will create business value for your company. Some of those examples are listed above such as operational analytics and reporting, any machine learning, detection events and alarms.
You are using all of this data to create models or to create reports for the purpose of business value.

Anything that could lower operations, lower energy costs, increase visibility into sustainability to can reach your ESG targets, and then also increase your return on assets. A lot of this data has a lot of valuable purposes if it’s used in the right way and used for the right use cases.
Fusion is doing exactly that – taking all of those data from all those “things,” acquiring it from all of those different locations, and then creating that industrial analytics data hub to use that data for any analytics they want to do and ultimately create business value.
The first of the Fusion Fundamentals series with Suchi Badrinarayanan, Business Consultant, at Fusion. This series will focus on liberating and normalizing OT data to accelerate enterprise-wide adoption and high business value realization of AI/ML. This first topic is how to Enable Industrial Data Analytics.
We’ve generally seen that there seems to be a big divide between the data coming from your sources and those who want to do the analytics related to that data.

Look on the left-hand side of this photo; you can see a couple of different sources you can get information from. Most people are trying to get time series information from the site, corporate historians, or even the operations management systems. But in addition, we’ve seen a lot of new sources that people are using, for example, IoT devices and instrument analyzers. All of these data sources need to land in a place where the analytics team can access them efficiently, and the data quality and reliability are also intact.
Generally, what we’ve heard from people trying to get access to that data is as follows:
At Fusion, we’re trying to use that data for is really any of the BI (Business Intelligence) or Analytics teams. So on the right-hand side of the photo above, you can see many different ways people can use that data. One way is digital twins, but again everyone is trying to get that data in the spot where they can either do just general BI or use that to make ML or AI models.
When we are talking to customers, there are a couple of things that always come to mind.

The problem of secure and scalable extraction, too many sources and formats, and industrial manufacturing pressures are the three that come to mind.
The first regarding secure and scalable extraction really stands out. That data is typically behind multiple firewalls and needs to go through multiple layers of security. It is necessary to make sure that the data streams that are coming out are incredibly scalable. So that the data can potentially work with millions of tags because the data source is so rich and has that much information in it.
The other thing that we’ve been recently hearing is that there are a lot of sources of data and a lot of formats of data. So people might have multiple different historians across their enterprise but also might have different formats for that data as well. That makes it even more challenging for analytics people to go and access that data because it’s not all in one easy-to-use format.
Any kind of “do it yourself mechanism” takes way too long, and people who have these use cases need that data and are not usually willing to wait the three months to a year that it might take for someone to ramp up and create this architecture all by themselves.

This is exactly where Fusion comes into play by connecting the data with the use cases. What we’ve created with Fusion is a Cloud-Native Industrial Analytics Data Hub. All of the data that’s there and is replicated from your source systems on your left-hand side gets the data there securely and reliably and, most importantly, analytics-ready.
Whatever use case you have after that, whether it’s Pipeline Integrity, ESG reporting, or even Anomaly Detection, all of that data can be accessed directly from Fusion.